AI-First Development: A Modern Curriculum for AI Application Developers in 2026

AI-First Development: A Modern Curriculum for AI Application Developers in 2026
1. Introduction: The Stochastic Barrier
Imagine debugging a function that is syntactically correct, logically sound, but fundamentally non-deterministic. You feed it the same input twice, and the output drift is subtle—perhaps a change in tone, or a slight hallucination in a retrieval task. Welcome to the reality of the AI Application Engineer in 2026.
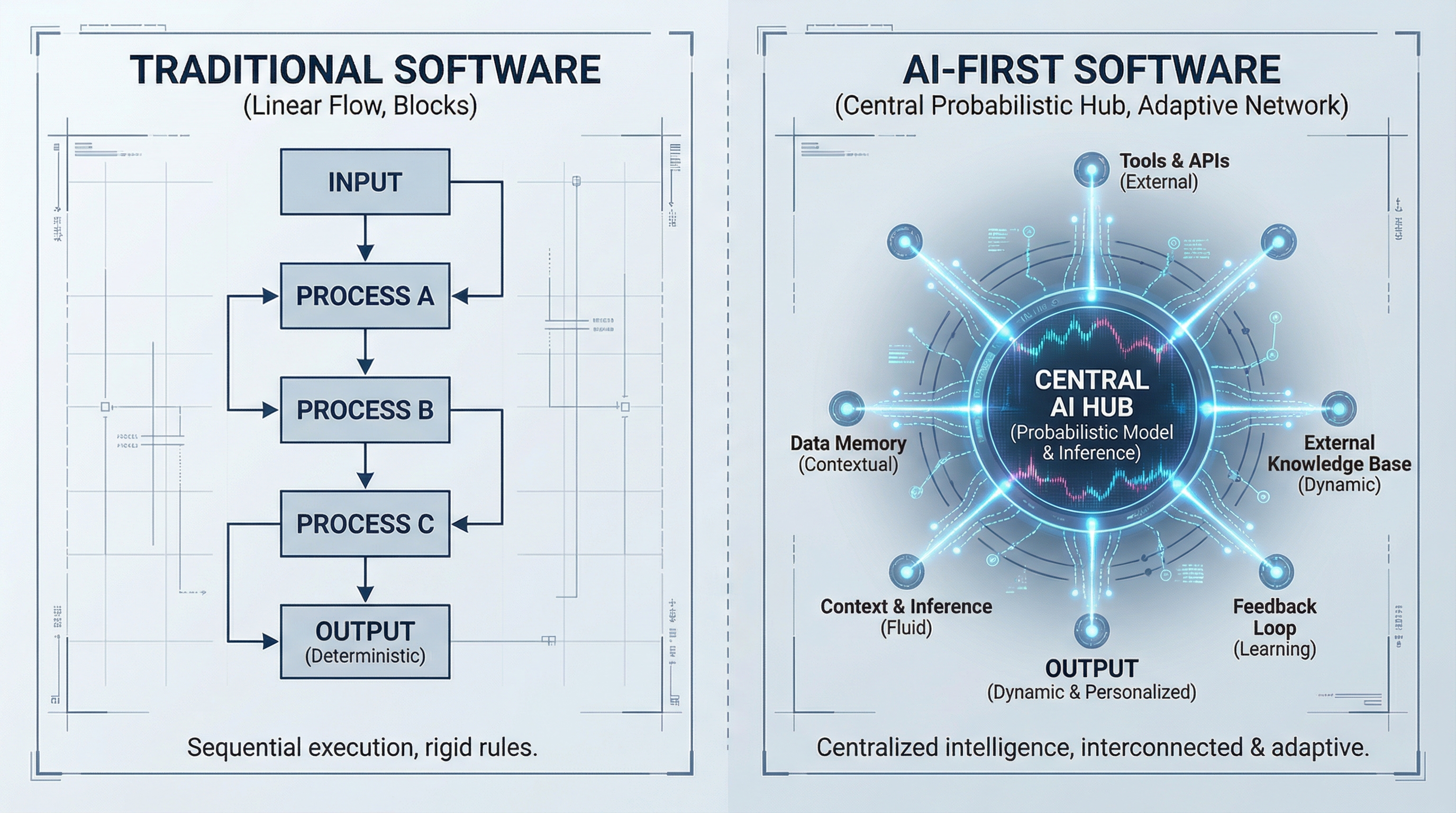
For the past decade, software engineering has been predicated on deterministic logic: if X, then Y. However, the shift to AI-First development requires a cognitive reframing from deterministic control to probabilistic orchestration. As an Applied Physicist, I view Large Language Models (LLMs) not as magic boxes, but as thermodynamic systems minimizing entropy in text generation. Your job is no longer just writing loops; it is managing the state, context, and temperature of these systems to collapse the wave function of possibility into a single, useful, executable action.
In 2026, "AI-First" does not mean slapping a chatbot on a legacy CRUD app. It means designing the application architecture around the capabilities and limitations of frontier models (like GPT-5 class or Gemini Ultra iterations). It means the database schema, the user interface, and the API surface area are all optimized to feed context to an inference engine.
This post outlines a rigorous, project-based curriculum to take you from a senior software engineer to an elite AI architect. We will move beyond the "hype" of basic prompting and delve into the physics of embeddings, the architecture of agentic loops, and the rigorous engineering of RAG (Retrieval-Augmented Generation) pipelines.
2. Theoretical Foundation: The Physics of Latent Space
To build robust AI applications, one must understand the substrate: the High-Dimensional Vector Space (or Latent Space). When we discuss "meaning" in AI, we are mathematically discussing geometry.
2.1 The Geometry of Semantics
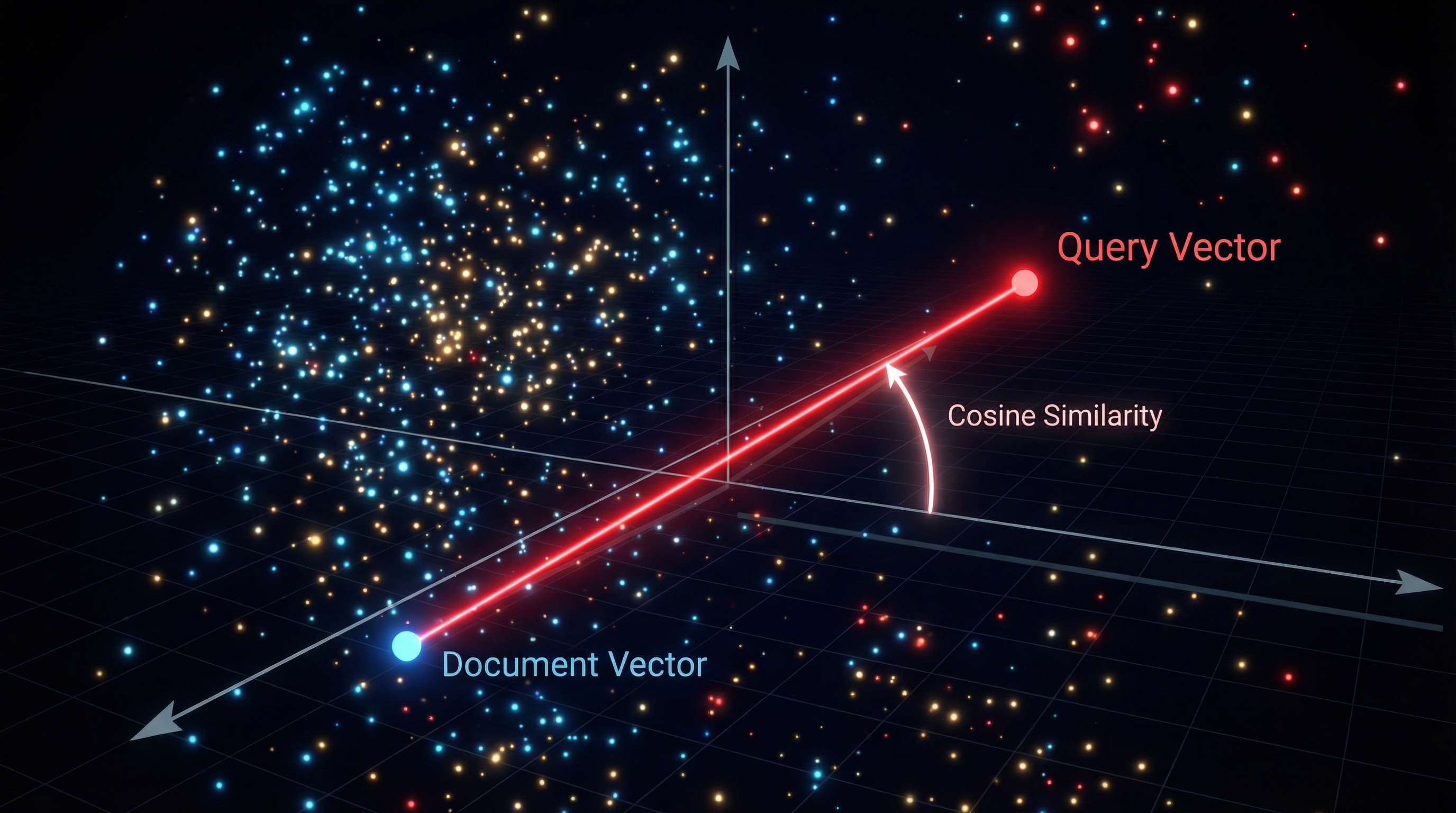
Modern embedding models map discrete tokens into continuous vector spaces, typically with dimensions ranging from 768 to 3072. A concept is no longer a string; it is a vector .
Semantic similarity is quantified not by string matching, but by the angle between vectors. The primary metric is Cosine Similarity:
Why does this matter for application design? Because "hallucination" often occurs when the retrieval mechanism fetches vectors that are orthogonally irrelevant (perpendicular in vector space) or when the density of the information in the latent manifold is too sparse.
2.2 Entropy and Sampling
When a model generates text, it is sampling from a probability distribution. The parameter Temperature () scales the logits () before the softmax function is applied:
As , the distribution peaks around the most likely token (Greedy Decoding), acting deterministically. As , the distribution flattens towards uniform randomness (maximum entropy).
The Curriculum Pivot: Most "AI courses" teach you to call an API. An elite curriculum teaches you that high-stakes agents (e.g., executing code) require , while creative assistants require dynamic temperature adjustment. You are essentially managing the thermodynamic state of your application's intelligence layer.
3. Implementation Deep Dive: From RAG to Agents
We will construct the skeleton of a modern 2026 AI application. We move beyond simple scripts to robust, type-safe, and observable architectures.
Phase 1: Context-Aware Retrieval (The RAG Backbone)
In 2026, naive RAG (chunking text and retrieving the top-k) is insufficient. We use Hybrid Search (Dense Vectors + Sparse Keywords) with Re-ranking. Here is a Python implementation using a modern orchestrator pattern.
import numpy as np from typing import List, Dict, Any from pydantic import BaseModel, Field # Mocking external dependencies for the sake of the example # Assume these wrap standard libraries like ChromaDB or Qdrant class VectorStore: def hybrid_search(self, query_vec: List[float], query_text: str, k: int = 5) -> List[Dict]: # In reality, this combines dot-product search with BM25 keyword matching # followed by a Cross-Encoder re-ranking step. return [{"content": "Retrieved context snippet...", "score": 0.92}] class RAGPipeline: def __init__(self, vector_store: VectorStore, embedding_model): self.store = vector_store self.embedder = embedding_model def retrieve_context(self, query: str) -> str: """ Performs Hybrid Search: 1. Dense Retrieval (Semantic) 2. Sparse Retrieval (Keywords) 3. Re-ranking (Cross-Encoder) """ # 1. Vectorize the query query_vec = self.embedder.encode(query) # 2. Retrieve candidates results = self.store.hybrid_search(query_vec, query, k=10) # 3. Filter by confidence threshold (The 'Noise Floor') # If the cosine similarity is below 0.75, it's likely noise. valid_results = [r["content"] for r in results if r["score"] > 0.75] if not valid_results: return "No relevant context found in the knowledge base." return " --- ".join(valid_results)
Usage Logic
pipeline = RAGPipeline(store, embedder)
context = pipeline.retrieve_context("How do I reset the pressure valve?")
### Phase 2: Deterministic Output via Structured Engineering
One of the biggest hurdles is getting JSON out of a probabilistic model. We enforce schema constraints using Pydantic.
```python
from pydantic import BaseModel
from typing import Literal, List
import json
# Define the Schema - The Model MUST adhere to this
class ActionPlan(BaseModel):
reasoning: str = Field(description="Chain of thought explaining the decision")
tool_choice: Literal["search_database", "calculate_risk", "escalate_to_human"]
parameters: Dict[str, Any] = Field(description="Arguments for the tool")
confidence_score: float
def generate_structured_action(user_query: str, context: str, llm_client) -> ActionPlan:
"""
Uses 'Function Calling' or 'JSON Mode' to force deterministic structure.
"""
system_prompt = """
You are an autonomous agent.
Analyze the user query based on the context.
You MUST output valid JSON matching the ActionPlan schema.
"""
response = llm_client.chat.completions.create(
model="gpt-4o-2026-snapshot",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Context: {context}
Query: {user_query}"}
],
response_format={"type": "json_object"} # Enforce JSON
)
# Parse and Validate - This raises an error if the LLM hallucinates the schema
raw_json = json.loads(response.choices[0].message.content)
return ActionPlan(**raw_json)
Phase 3: The ReAct Agent Loop
The most advanced pattern for 2026 is the Agentic Loop (Reason, Act, Observe). This turns the LLM into an Operating System process.
def agent_loop(query: str, max_iterations: int = 5): history = [{"role": "user", "content": query}] for i in range(max_iterations): # 1. PLAN: Ask the model what to do next response = llm_generate(history) # 2. DECIDE: Check if the model wants to run a tool if "<tool_call>" in response: tool_name, tool_args = parse_tool(response) print(f"[Iteration {i}] Executing {tool_name}...") # 3. ACT: Execute Python code or API call try: observation = execute_tool(tool_name, tool_args) except Exception as e: observation = f"Error executing tool: {str(e)}" # 4. OBSERVE: Feed the result back into history history.append({"role": "assistant", "content": response}) history.append({"role": "tool", "content": observation}) else: # The model is done and providing the final answer return response return "Agent exceeded maximum iterations without resolution."
4. Advanced Techniques & Optimization
Moving from a prototype to production requires addressing latency, cost, and safety. In the 2026 landscape, we focus on Prompt Caching and Speculative Decoding.
4.1 Latency Optimization: Prompt Caching
Context windows have grown to millions of tokens, but re-sending 100k tokens of documentation for every query is prohibitively slow and expensive. Modern architectures use Prefix Caching. The massive system prompt and RAG context are cached at the inference layer. You only pay compute for the delta (the new user query).
4.2 Evaluation: LLM-as-a-Judge
How do you unit test a probabilistic system? You cannot assert result == "expected_string". Instead, you use a stronger model (the "Judge") to evaluate the output of your application model.
The Metric: Relevance, Faithfulness, and Recall.
- Faithfulness: Is the answer derived only from the retrieved context? (Prevents hallucinations).
- Relevance: Does the answer actually address the user query?
4.3 Guardrails and Red-Teaming
Never expose raw model outputs to users. You must implement a deterministic "Guardrail" layer (e.g., NVIDIA NeMo Guardrails or bespoke regex filters) to intercept PII (Personally Identifiable Information), toxicity, or prompt injection attacks. In 2026, security is not an afterthought; it is a blocking step in the CI/CD pipeline.
5. Real-World Applications
Where is this actually used? The "Chat with PDF" era is over. Here are the verticals demanding this curriculum:
1. Legal & Compliance Automation: Law firms are using Agentic RAG to traverse millions of case files. The challenge here isn't just retrieval; it's multi-hop reasoning. The model must retrieve a statute, realize it references a precedent, retrieve that precedent, and synthesize the connection. This requires the "Agent Loop" architecture described above, capable of maintaining a reasoning trace over minutes of computation.
2. Biological Research & Drug Discovery: Using multimodal models to analyze molecular structures (images/graphs) alongside research papers (text). An AI-first app here acts as a lab partner, suggesting synthesis pathways by correlating visual data of protein folding with textual data from recent arXiv papers.
3. DevOps & SRE Autonomy: "Self-healing infrastructure." An agent connects to the logs (Splunk/Datadog), detects an anomaly, retrieves the relevant runbook via RAG, and generates a Terraform patch to fix the drift. The "Human-in-the-loop" validates the Plan object before the Agent executes the Act step.
6. External Reference & Video Content
Recommended Video: "Intro to Large Language Models" by Andrej Karpathy (or his successor content on "LLM OS").
Summary & Relevance: While slightly dated by 2026 standards, Karpathy's conceptualization of the LLM as the Kernel of a new Operating System remains the definitive mental model for this curriculum. He explains that the LLM is not just a text generator, but the central processing unit orchestrating IO (tools), Memory (Context Window/Vector DB), and Processing (Reasoning). Watching this helps you transition from thinking of AI as a "feature" to thinking of it as the "computer" itself, which is critical for the AI-First mindset.
7. Conclusion & Next Steps
The transition to AI-First development is the most significant shift since the adoption of Cloud Computing. We have moved from writing deterministic recipes to orchestrating probabilistic agents.
Your Roadmap for the next 12 weeks:
- Month 1: Master the RAG Pipeline. Don't just copy code; understand the vector math and re-ranking logic.
- Month 2: Build Agents. Implement the ReAct loop. Learn to handle the state of a conversation and manage tool execution errors.
- Month 3: Multimodal & Ops. Integrate vision. Build an eval harness using LLM-as-a-Judge to measure your system's drift.
Stop treating AI as a black box. You are a physicist of information; the model is your laboratory. Build accordingly.