Case Study: Migrating a Monolith to Serverless Microservices

Case Study: Migrating a Monolith to Serverless Microservices
1. Introduction: The Entropy of the Monolith
In the domain of software engineering, systems tend to evolve toward chaos. This is not merely a poetic observation but a reflection of the Second Law of Thermodynamics applied to codebase complexity. We begin with a clean, structured monolithic application—a single executable deployment unit. Initially, it is efficient. Network latency is zero for internal function calls, and transactional integrity (ACID) is guaranteed by a single database connection.
However, as features accumulate, the system’s mass increases. The gravitational pull of dependencies makes refactoring impossible. I recently consulted for a FinTech enterprise struggling with what I call a "Black Hole Monolith." Their core ledger system, written in a legacy Node.js/Express framework, had accumulated over 500,000 lines of code. Deployment pipelines took 45 minutes to compile and test. A single memory leak in the reporting module would crash the authentication service, taking the entire platform offline. The coupling was absolute; the entropy was maximum.
This post details the surgical extraction of that monolith into a distributed, event-driven serverless architecture on AWS. We are not simply "splitting code"; we are engaging in a phase transition. We are moving from a state of high cohesion and high coupling to a distributed state requiring eventual consistency, idempotent operations, and rigorous fault tolerance. This case study explores the physics of distributed systems, the mathematics of graph partitioning, and the concrete TypeScript implementation of the "Strangler Fig" pattern to achieve zero-downtime migration.
2. Theoretical Foundation: Graph Partitioning and Queueing Theory
To understand migration, we must stop viewing code as text and start viewing it as a directed graph , where represents modules (classes, functions) and represents dependencies (calls, imports).
The Graph Partitioning Problem
In a monolith, the graph density is high:
Our objective is to partition into subgraphs (microservices) such that we minimize the "cut size"—the number of edges crossing between partitions. These crossing edges represent network calls, which introduce latency and failure modes. We optimize for high intra-subgraph cohesion and low inter-subgraph coupling.
System Dynamics and Little’s Law
One of the primary arguments for serverless is infinite scaling potential, but this is constrained by Little’s Law. In a stable system:
Where:
- is the average number of items in the system (concurrency).
- is the average arrival rate (requests/sec).
- is the average time an item spends in the system (latency).
In a monolith, is capped by the server's thread pool or CPU cores. When spikes, must increase (queueing), or requests drop. In a serverless environment (e.g., AWS Lambda), is virtually unbounded (up to account limits), allowing us to handle massive spikes without increasing , provided downstream resources (databases) can handle the throughput.
CAP Theorem and Eventual Consistency
Moving to microservices forces a confrontation with the CAP theorem. We sacrifice Consistency (C) for Availability (A) and Partition Tolerance (P). We move from immediate consistency:
to eventual consistency, where the state converges over time :
This theoretical shift dictates our implementation strategy: we cannot simply replace function calls with HTTP requests. We must adopt asynchronous event passing to decouple the temporal dependency between services.
3. Implementation Deep Dive
The migration strategy we employed is the Strangler Fig Pattern. We place an API Gateway in front of the monolith and gradually route specific endpoints to new serverless microservices, while the monolith handles the rest. We will focus on extracting the "Order Processing" module.
Step 1: The Facade (Anti-Corruption Layer)
First, we establish a routing logic. This is often done at the load balancer level (ALB) or API Gateway. However, for complex logic, we might need a programmable router. Below is a TypeScript representation of a routing decider that facilitates canary deployments.
/** * Router Logic: Determining whether to serve traffic via Legacy Monolith or * the new Serverless Microservice based on feature flags and user segments. */
interface ServiceRoute { target: 'MONOLITH' | 'SERVERLESS'; version: string; }
interface UserContext { userId: string; tier: 'FREE' | 'PREMIUM'; }
// Deterministic hashing for stable canary routing function getUserHash(userId: string): number { let hash = 0; for (let i = 0; i < userId.length; i++) { const char = userId.charCodeAt(i); hash = ((hash << 5) - hash) + char; hash = hash & hash; // Convert to 32bit integer } return Math.abs(hash); }
export function routeRequest(user: UserContext, trafficPercentage: number): ServiceRoute { // Edge Case: Always route premium users to stable monolith during initial alpha if (user.tier === 'PREMIUM' && trafficPercentage < 100) { return { target: 'MONOLITH', version: 'v1.0' }; }
const threshold = trafficPercentage / 100; const normalizedHash = (getUserHash(user.userId) % 100) / 100;
if (normalizedHash < threshold) { return { target: 'SERVERLESS', version: 'v2.0-beta' }; }
return { target: 'MONOLITH', version: 'v1.0' }; }
### Step 2: The Serverless Handler (Stateless Compute)
The new microservice is an AWS Lambda function. Unlike the monolith, it cannot rely on in-memory sessions or connection pooling in the same way. We must handle database connections efficiently outside the handler scope to utilize execution context reuse.
```typescript
/**
* OrderServiceLambda.ts
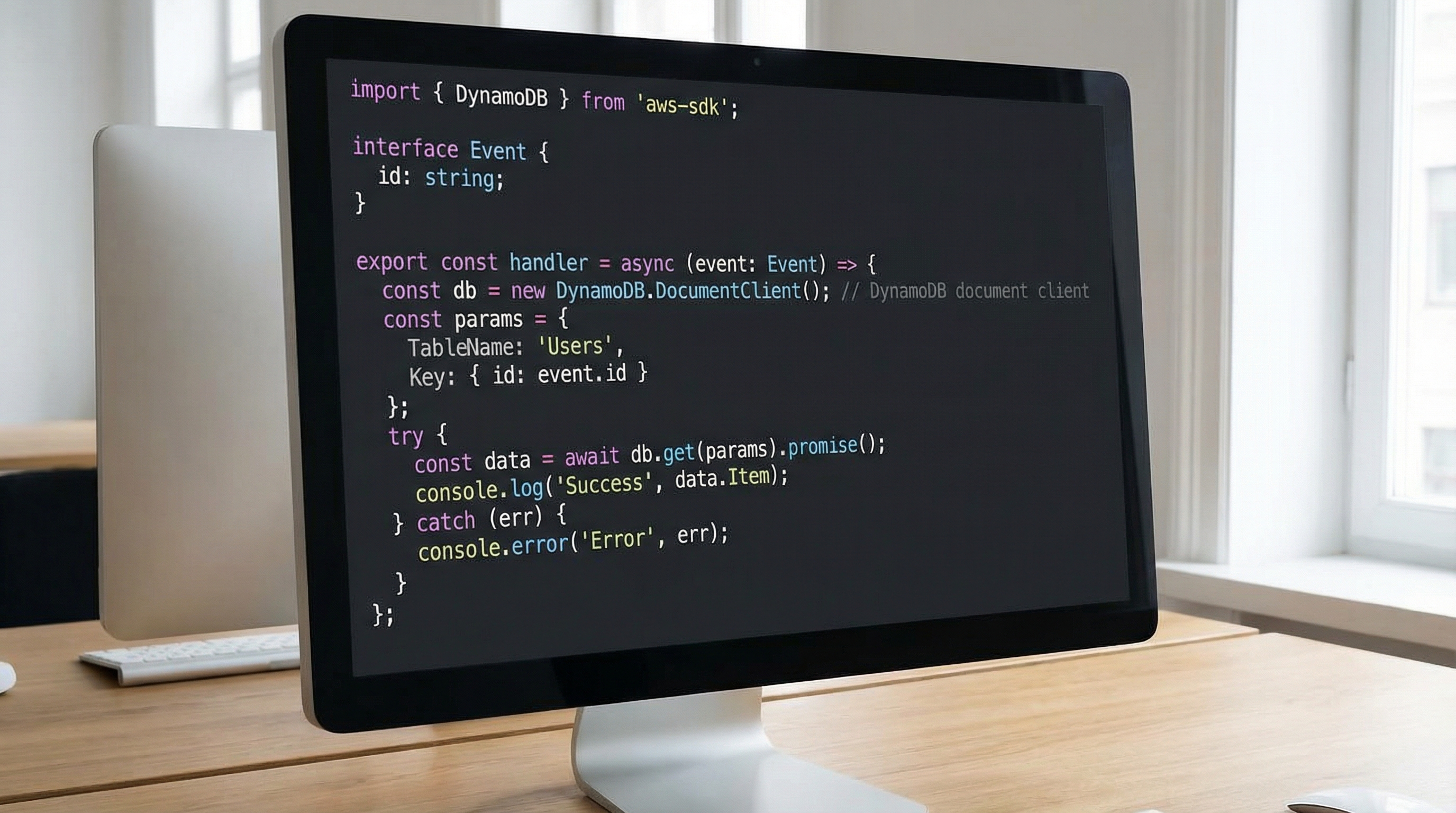
* Handles order creation with idempotency checks and DynamoDB persistence.
*/
import { DynamoDBClient } from '@aws-sdk/client-dynamodb';
import { DynamoDBDocumentClient, PutCommand } from '@aws-sdk/lib-dynamodb';
import { APIGatewayProxyEvent, APIGatewayProxyResult } from 'aws-lambda';
// Initialize outside handler for connection reuse (Warm Starts)
const client = new DynamoDBClient({ region: 'us-east-1' });
const docClient = DynamoDBDocumentClient.from(client);

interface OrderPayload { orderId: string; userId: string; items: any[]; total: number; }
export const handler = async (event: APIGatewayProxyEvent): Promise<APIGatewayProxyResult> => { try { const payload: OrderPayload = JSON.parse(event.body || '{}');
// Input Validation (Fail Fast)
if (!payload.orderId || !payload.userId) {
return { statusCode: 400, body: JSON.stringify({ error: 'Missing required fields' }) };
}
// IDEMPOTENCY CHECK: Ensure we don't process the same order twice
// Using a conditional put: "attribute_not_exists(PK)"
const command = new PutCommand({
TableName: process.env.TABLE_NAME,
Item: {
PK: `ORDER#${payload.orderId}`,
SK: `USER#${payload.userId}`,
...payload,
createdAt: new Date().toISOString(),
status: 'PENDING'
},
ConditionExpression: 'attribute_not_exists(PK)'
});
await docClient.send(command);
return {
statusCode: 201,
body: JSON.stringify({ message: 'Order created', id: payload.orderId })
};
} catch (error: any) { // Specific error handling for Idempotency failures if (error.name === 'ConditionalCheckFailedException') { return { statusCode: 200, // Return 200 OK for idempotent retries body: JSON.stringify({ message: 'Order already exists', id: JSON.parse(event.body!).orderId }) }; }
console.error('System Failure:', error);
return { statusCode: 500, body: JSON.stringify({ error: 'Internal Server Error' }) };
} };
### Step 3: Data Synchronization (Dual-Write Strategy)
During the migration phase, data must exist in both the Monolith's SQL database (e.g., PostgreSQL) and the new Microservice's NoSQL database (DynamoDB). We use a **Dual-Write** strategy, or preferably, a **CDC (Change Data Capture)** pattern. Below is a simplified Dual-Write implementation within the legacy monolith to ensure new data flows to the new system.
```typescript
/**
* LegacyMonolithController.ts
* Implementing Dual-Write to bridge the gap during migration.
*/
import { Pool } from 'pg';
import { EventBridgeClient, PutEventsCommand } from '@aws-sdk/client-eventbridge';
const dbPool = new Pool({ /* config */ });
const ebClient = new EventBridgeClient({ region: 'us-east-1' });
async function createOrderLegacy(order: any) {
const client = await dbPool.connect();
try {
await client.query('BEGIN');
// 1. Write to Legacy SQL
const sqlText = 'INSERT INTO orders(id, user_id, amount) VALUES($1, $2, $3) RETURNING *';
const res = await client.query(sqlText, [order.id, order.userId, order.amount]);
// 2. Publish Domain Event for the New System (Asynchronous)
// We do NOT write directly to DynamoDB here to avoid distributed transaction complexity.
// We emit an event, and the new system consumes it.
await ebClient.send(new PutEventsCommand({
Entries: [{
Source: 'legacy.monolith',
DetailType: 'OrderCreated',
Detail: JSON.stringify(order),
EventBusName: 'migration-bus'
}]
}));
await client.query('COMMIT');
return res.rows[0];
} catch (e) {
await client.query('ROLLBACK');
// If EventBridge fails, we might still rollback the SQL transaction
// OR log to a dead-letter file to ensure consistency.
throw e;
} finally {
client.release();
}
}
4. Advanced Techniques & Optimization
Migrating to serverless exposes new dimensions of engineering challenges, primarily centered around Cold Starts, Concurrency Limits, and Distributed Tracing.
Optimization 1: Mitigating Cold Starts via Stochastic Provisioning
AWS Lambda functions go dormant after inactivity. When a new request arrives, the environment must bootstrap (download code, start runtime). This introduces latency (100ms - 1s). For our FinTech client, this was unacceptable for high-frequency trading endpoints.
We utilized Provisioned Concurrency, but optimizing the cost requires mathematical modeling. If the arrival rate follows a Poisson process, we calculate the probability of a request waiting using Erlang-C formulas. However, web traffic is often bursty (Pareto distribution). We implemented an auto-scaler that predicts traffic based on historical Fourier analysis (detecting daily/weekly cycles) and pre-warms environments 5 minutes before predicted spikes.
Optimization 2: The Thundering Herd & Exponential Backoff
When a microservice fails, retries can overwhelm the system. If 1000 requests fail and all retry simultaneously, the recovering service immediately crashes again. We implement Jittered Exponential Backoff.
The sleep time is calculated as:
This randomness decouples the retry attempts, flattening the spike into a manageable curve.
Optimization 3: Distributed Tracing with OpenTelemetry
In a monolith, debugging is reading a single log file. In microservices, a request spans Gateway -> Lambda A -> EventBridge -> Lambda B -> DynamoDB. We mandated the use of AWS X-Ray and OpenTelemetry. Every request is tagged with a Correlation-ID at the ingress. This ID is propagated through HTTP headers and event payloads. We visualize the "Trace Map" to identify bottlenecks (e.g., a DynamoDB Scan operation slowing down the entire chain).
5. Real-World Applications
The architecture described above is not hypothetical. It is the industry standard for modernizing high-scale systems.
- E-Commerce (Inventory Management): During Black Friday, inventory checking is the most read-heavy operation. By extracting Inventory to a serverless microservice using DynamoDB (with DAX caching), retailers decouple browsing traffic from the checkout monolith. If the checkout monolith slows down, users can still view products rapidly.
- Media Streaming: Companies like Netflix and Disney+ utilize similar patterns for metadata ingestion. When a new movie is uploaded, it triggers a cascade of serverless functions: transcoding, subtitle extraction, and thumbnail generation. Doing this in a monolith would block the main application threads for hours.
- IoT Telemetry: In a smart grid project, millions of meters send usage data every 15 minutes. A monolithic API falls over under this synchronized write pressure. Serverless functions combined with Kinesis Data Streams allow the system to buffer the influx and process data in batches, smoothing out the load on the backend database.
6. External Reference & Video Content
I strongly recommend reviewing the video "Microservices Migration". This resource visually articulates the "Strangler Fig" pattern I demonstrated in the implementation section.
The video highlights a critical decision matrix: Complexity vs. Agility. It corroborates our theoretical findings that while microservices increase operational complexity (deployment, monitoring, tracing), they significantly decrease development complexity for individual teams. The speaker reinforces the importance of the "Anti-Corruption Layer"—the exact facade logic we implemented in TypeScript—to prevent the new clean domain model from being polluted by the legacy schema. It serves as an excellent visual companion to the code provided here.
7. Conclusion & Next Steps
Migrating a monolith to serverless microservices is an exercise in managing entropy. We are trading the compile-time coupling of a monolith for the run-time coupling of a distributed system.
Key Takeaways:
- Physics of Data: Data has gravity. Moving compute is easy; moving data is hard. Use Dual-Write and Event Sourcing to bridge the gap.
- Mathematical Rigor: Apply queueing theory (Little's Law) to understand scaling limits and backoff strategies to handle failure modes.
- Code implementation: The Facade (Router), the Handler (Compute), and the Event Bus (Communication) are the three pillars of this architecture.
Next Steps:
Do not attempt a "Big Bang" rewrite. Identify a low-risk, edge-facing module (like Notifications or PDF generation). distinct from the core business logic. Implement the facade pattern. Monitor the Correlation-ID traces. Once you stabilize the event-driven consistency model, proceed toward the core. The goal is not just to use serverless, but to achieve architectural velocity.